The Envisage project has 3 different industrial case studies, this blog post provides a brief overview of one of them – large-scale offline search for mobile and wearable devices (inspired by Hitchhiker’s Guide to the Galaxy), followed by a repost of the feasibility of doing large-scale offline search on mobile devices.
The purpose of the search case study is to investigate the correspondence between user and system level SLAs with system metrics in order to run the supporting cloud service as efficiently as possible while fulfilling the SLAs, in particular through simulation of scenarios with tools and techniques developed in Envisage (e.g. based on ABS Language and Tools).
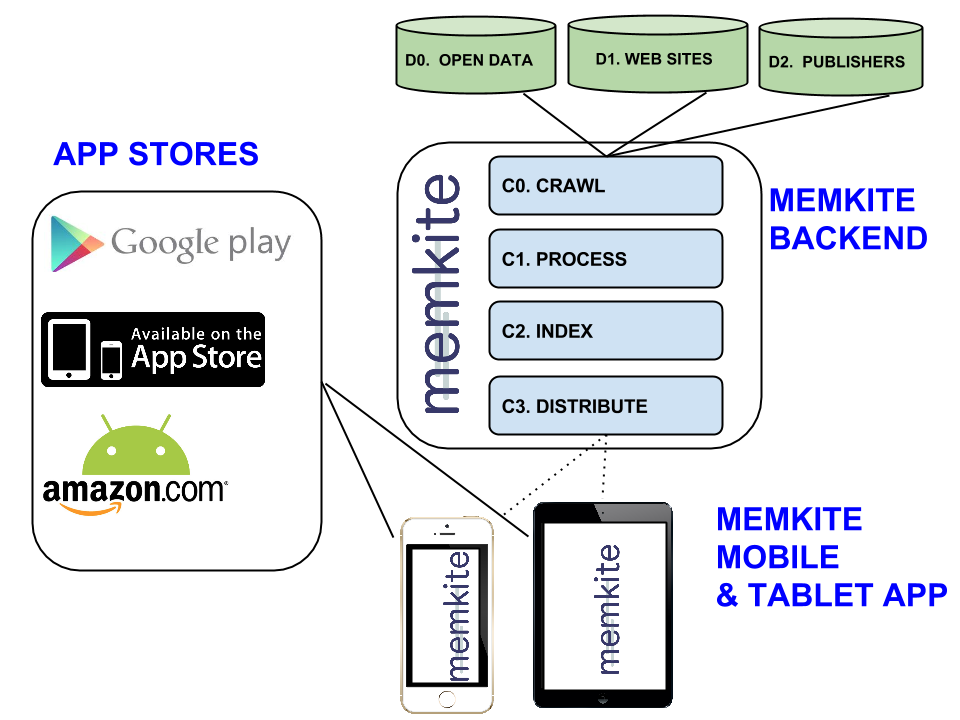
There are 3 main themes for this cloud service as shown in figure above:
- Crawling of Data to Cloud Service
- Processing and Indexing of Data in Cloud Service
- Distribution of Indexed Data to Mobile Customers
Technical Feasibility of Building Hitchhiker’s Guide to the Galaxy, i.e. Offline Web Search – Part I
Memkite (@memkite) is a startup building the equivalent of Hitchhiker’s Guide to the Galaxy, see iOS App Store for a very early (and small) version. In this blog post we’ll discuss the technical feasibility of building Hitchhiker’s Guide to the Galaxy.

BBC recently released a 30th year anniversary game for Hitchhiker’s Guide to the Galaxy. While being an interesting fictional book in itself, it also presents many interesting technological innovations. One of them being the Hitchhiker’s Guide to the Galaxy – “the Guide” – described as: “the standard repository for all knowledge and wisdom” (personal belief: can be created)
1. What would a 2014 realization of “the Guide” look like?
Web Search engines – such as the 4 major ones: Baidu, Bing, Google and Yandex – represent a lot of the functionality one would want in an implementation of the Hitchhiker’s Guide, i.e. “the standard repository for all knowledge and wisdom”.
But the problem with the web search engines are that they don’t work well in outer space:
- when you’re not connected to the Internet, e.g. when traveling far into space (as the intention for “the Guide”),
- search latency in space tend to be VERY high, e.g. even for nearby planets such as Mars (and the Mars One expedition) the search latency would provide a very poor user experience (even in 2018 when Mars is only 57.6 million kilometers away a signal at full lightspeed (i.e. 0,299792458 million kilometers/second) it would still need 6.4 minutes to get a ping at best, and even more than that to get a search result due to communication protocol overhead.
2. Ok, so the Guide will resemble Web Search, but how to get that working in space?
What if you could put a web search like index and content on a device? Storage technologies can enable that:

Fortunately computational storage is growing tremendously fast both in capacity and speed, e.g. last year Kingston released a (tiny) 1 TeraByte SSD Disk packaged in a USB Stick. This USB stick has more storage capacity than Google and Altavista had combined on their search clusters back in the late 90s, and the latency of SSD storage is roughly about 1/100th compared to individual disks back then.

Other examples of recently launched high-capacity mobile storage is Sandisk’s 128 GB MicroSDXC card, it is so space-efficient – dimensions: 15 mm x 11 mm x 1.0 mm (.59in x.043in x.03in) that you can fit approximately 0.775 TeraByte of storage per cubic cm(!) – for comparison: the iPad Air is approximately 300 cubic cm (240 mm x 169.5 mm x 7.5 mm)
![]()
Flash/SSD storage works nicely, but another very promising forthcoming storage technology is RRAM (developed by Crossbar Inc). It allows storing 1 TeraByte on 2 square centimeter chip, and promises 20x lower power than Flash-based storage.
3. Cool enough.., but I don’t care much for late 90s Web Search, this is 2014 and I am going to space!
Good point, but let’s instead focus on your information needs that you need from “the Guide” while space traveling (lets for the sake of simplicity assume that you are a software engineer, but most the sources below are of general interest), e.g.
- Knowledge sources, e.g. Wikipedia, Stackoverflow, Quora, Academic Papers, Non-fictional books, Reddit, news.ycombinator.com.
- Commercial/Shopping-related information, e.g. Ebay, Amazon.com, Alibaba, Etsy, Rakuten and Yelp Listings
- Large sources of content (broad wrt types of content), e.g. Facebook.com, Blogger.com, Tumblr.com, Yahoo.com, Twitter.com and WordPress.com
- App Stores (plenty of time to try apps and games between destinations space..), e.g. iOS App Store, Google Play and Windows 8.
- Open Source repos, e.g. github.com, bitbucket.org etc.
- Entertainment (e.g. Netflix Movies, TV Shows, Youtube, Vine, Instagram, Flickr, Fictional Books, ++)
- All social network updates relevant for you.
- News updates, e.g. pick most popular content URLs published on Twitter
How would this work for you?
4. Yes, this will probably solve almost all my information needs, but this is infeasible to provide in space?!
 figure: early Lego-visualization of rough estimates of data source sizes on a 2 cm2 1 TeraByte RRAM chip
figure: early Lego-visualization of rough estimates of data source sizes on a 2 cm2 1 TeraByte RRAM chip
Understand your skepticism, but allow me to explain – with estimates for some of the above data sources – how this can be feasible to provide in space, even on single mobile device. You’ve probably used devices with FAT filesystems before, but they’re pretty thin compared to what I am going to show you.
| Data Source | Size in Gigabytes | Aggregate Size in Gigabytes | Aggregate cm^3 assuming stack of 128GB MicroSDHC | Aggregate cm^2 assuming 1 TeraByte RRAM | Comment |
|---|---|---|---|---|---|
 English Wikipedia |
10.67 | 10.67 | 0.013 | 0.021 | compressed with bzip2 of XML |
 StackoverFlow.com |
15 | 25.67 | 0.033 | 0.051 | compressed with 7z of XML |
 Quora.com (Estimate) |
30 – 60 | 55.67 – 85.67 | 0.071 – 0.110 | 0.111 – 0.171 | Estimate is that it is between 2-4 times larger than stackoverflow since search queries on Bing and Google site:quora.com vs site:stackoverflow.com supports that |
 Last 10 years of ALL Academic Papers (Estimate) |
3-10 GB per year (for 1.3-1.5M articles), 30-100 GB per decade | 85.67 – 185.67 | 0.071 – 0.239 | 0.171 – 0.371 | Rough Estimate based on comparing with Wikipedia |
 500000 Non-Fiction Textbooks |
50-60 | 130.67 – 245.67 | 0.168 – 0.316 | 0.261 – 0.491 | Rough estimate assuming average of 200-300 pages per book |
 App Store Pages |
10-30 | 140.67 – 275.67 | 0.181 – 0.355 | 0.281 – 0.551 | 2-5 million app description pages in total |
 News and content updates per day News and content updates per day |
200 | 340 – 475 | 0.438 – 0.612 | 0.680 – 0.950 | There are roughly 500M tweets published per day. On a sample with 10M tweets there were about 234K URIs with more than 1 occurence (i.e. rough popularity and quality measure) – scale this up to all tweets – 234K*(500M/10M) = 11.7M URIs – Assuming each URI points to a document with approximately 2400 words (average for top-ranked documents on the Web), and you only keep the top 2M of those 11.7M documents you get roughly 2 times the size Wikipedia per day. Assume you keep the last 10 days, i.e. only needing to download 20 GB / day – corresponding to approximately 3 minutes on a 1 GBit/s connection |
| Wikipedia Images – Baseline | 20 | 360-495 | 0.464 – 0.638 | 0.720 – 0.990 | Wikipedia has images with good Metadata, so can be used to spice up results in all/most rows above. In order to get full set of strongly compressed images (e.g. with HEVC) for all text data above one can probably multiply data sizes in each row with 2-3 (or pi) to get a rough estimate. Assuming one set aside 2 Terabyte for Images in HEVC Quality and size (ref 2KB representation of Mona Lisa), one could store almost 1 billion images. |
 Video |
5300 | 5660 – 5795 | 7.303 – 7.477 | 11.320 – 11.590 | Netflix has about 8900 movies, assuming each movie is 2 hours (120 minutes) and is encoded with good quality it would take roughly 8900*2*300 MB = 5.3 TeraByte (24 TB in HD). Have read that Netflix uses approximately 32.7% of Internet’s bandwidth capacity, so preinstalling Netflix on mobile devices may have noticeable effect on the Internet |

Figure: Visualization of storing what presented in the table above. setting: (simulated) RRAM chips placed on an iPad Air
Conclusion
Have shown that building hitch-hikers guide data and storage-wise is highly likely to be feasible. Will in the next posting talk more about algorithms, latency and other types of enabling hardware (e.g. CPUs, GPUs and Batteries) needed to enable searching this efficiently.

This is what we’re working on, feel free to reach out (e.g. investors, mobile hardware vendors, content providers in particular). We still have lots of work to do. So far, our app looks something like this. It’s got instant search, which works really smooth, even when fueled by 80GB of data.
Best regards,
Memkite Team – Thomas (thomas@memkite.com), Torbjørn (torb@memkite.com), Amund (amund@memkite.com)
This blog post is partially funded by the EU project FP7-610582 ENVISAGE: Engineering Virtualized Services (http://www.envisage-project.eu).